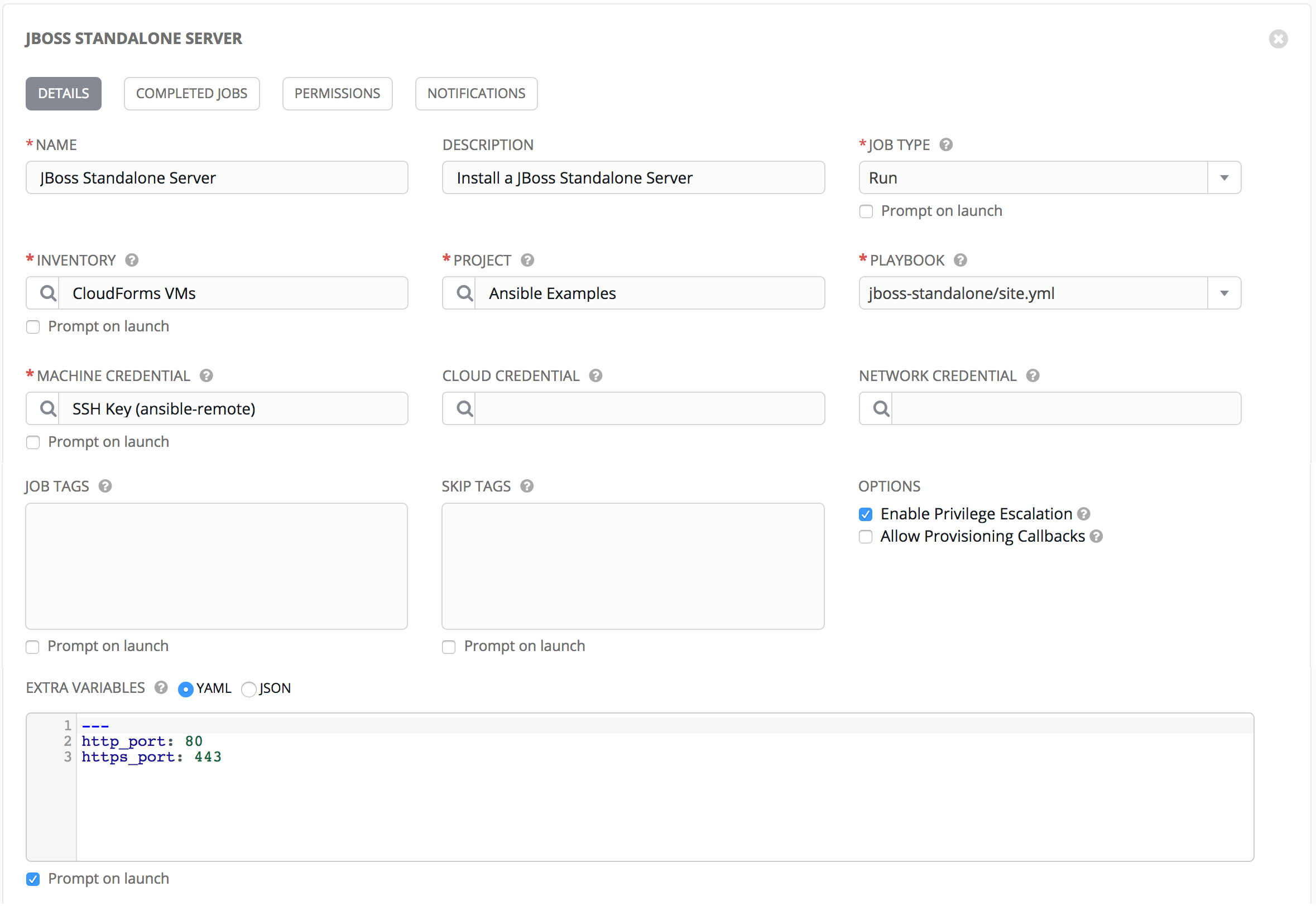
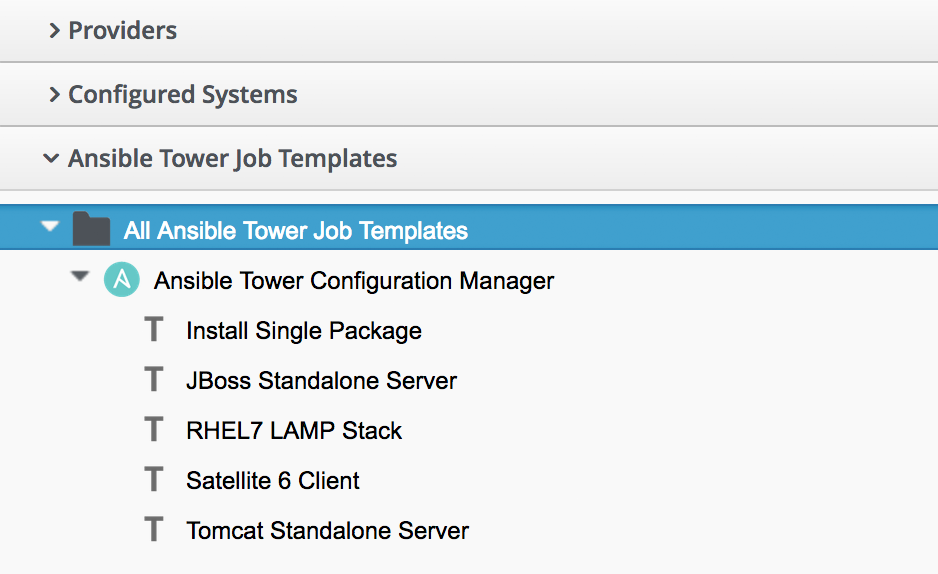
One of the most powerful features of Ansible as a configuration management tool is the relative simplicity and ease of understanding of its YAML-formatted playbooks. Adding the capability to be able to run Ansible playbooks from Automate as well as run Ruby methods presents us with a dilemma; when to use which?
Ruby methods allow us to access and manipulate all of the objects and their properties within the VMDB. We have a powerful scripting language at our disposal that allows us to make real-time decisions as part of our automation workflow. For example we can determine how many VMs are currently running on each hypervisor in a cluster before making placement decisions during provisioning. The disadvantage is that we need to be fairly comfortable with the Ruby scripting language and the Automate object model to take full advantage and start developing our own automation scripts.
Ansible playbooks allow us to harness the power of the Ansible module library to interact with many systems or infrastructure components in our enterprise that may not be natively supported by CloudForms or ManageIQ (such as load balancers for example). They allow us to do this using an easy to learn and well-documented YAML-based modelling language. We are also able to take advantage of the many thousands of existing Ansible roles that are downloadable from the Ansible Galaxy web site [1]
Whether we use Ruby methods or Ansible playbooks, we can still take advantage of some of the powerful Automate features such as state machines to build our workflows.