More Advanced Schema and Instance Features
Our Automate examples so far have used relatively simple class schema features. We have used the attribute and method field types, and we’ve seen how to store attributes as strings or encrypted passwords. We’ve called our instances using simple URI pathnames such as /General/Methods/HelloWorld, and our instances have run single methods. This simple type of schema allows us to create many different and useful instances, but there are times when we need additional flexibility. For example it is sometimes useful to be able to select which of several methods in our schema to run, based on criteria established at runtime.
There are three more class schema features that we can use to extend the usefulness of our instances: messages, assertions and collections.
Messages
Each schema field has a message column/value that we can optionally use to identify a particular field to execute or evaluate when we call the instance. We can think of this as a filter to determine which schema values to process.
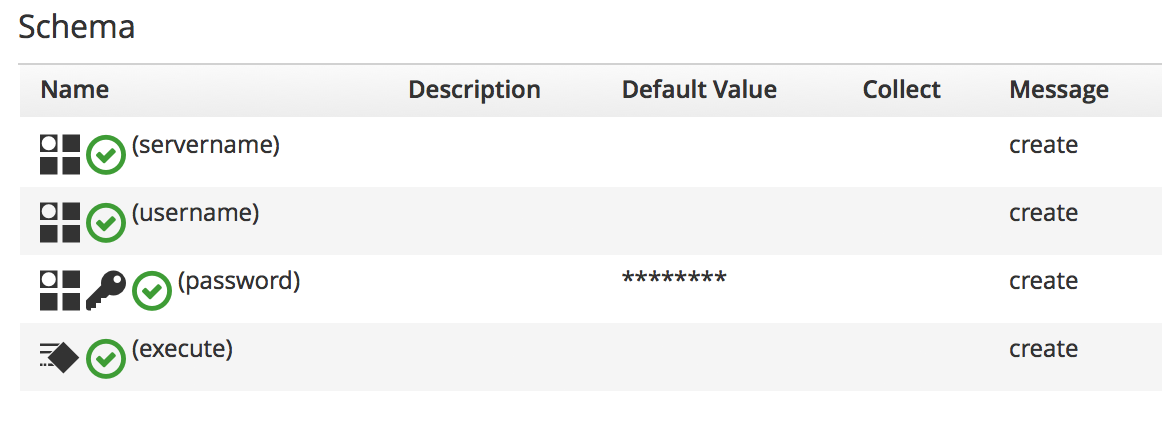
The default message is create, and if we look at the schema that we created for our /ACME/General/Methods class, we see that the default message value of create was automatically set for us for all fields (see The schema of the /ACME/General/Methods class, showing the message).
Figure 1. The schema of the /ACME/General/Methods class, showing the message
We specify the message when we create a relationship to an instance, by appending #message after the URI to the instance. If we don’t explicitly specify a message then #create is implicitly used.
For example we could create a relationship to run our first HelloWorld instance, using a URI of either:
/ACME/General/Methods/HelloWorld
or
/ACME/General/Methods/HelloWorld#create
In both cases the hello_world method would execute as this is the method schema field "filtered" by the create message.
Specifying our own Messages
It can be useful to create a class/instance schema that allows for one of several methods to be executed, depending on the message passed to the instance at runtime. For example the schema for the /Infrastructure/VM/Provisioning/Placement class allows for a provider-specific VM placement algorithm to be created, and selected using a message (see Schema for the /Infrastructure/VM/Provisioning/Placement class).
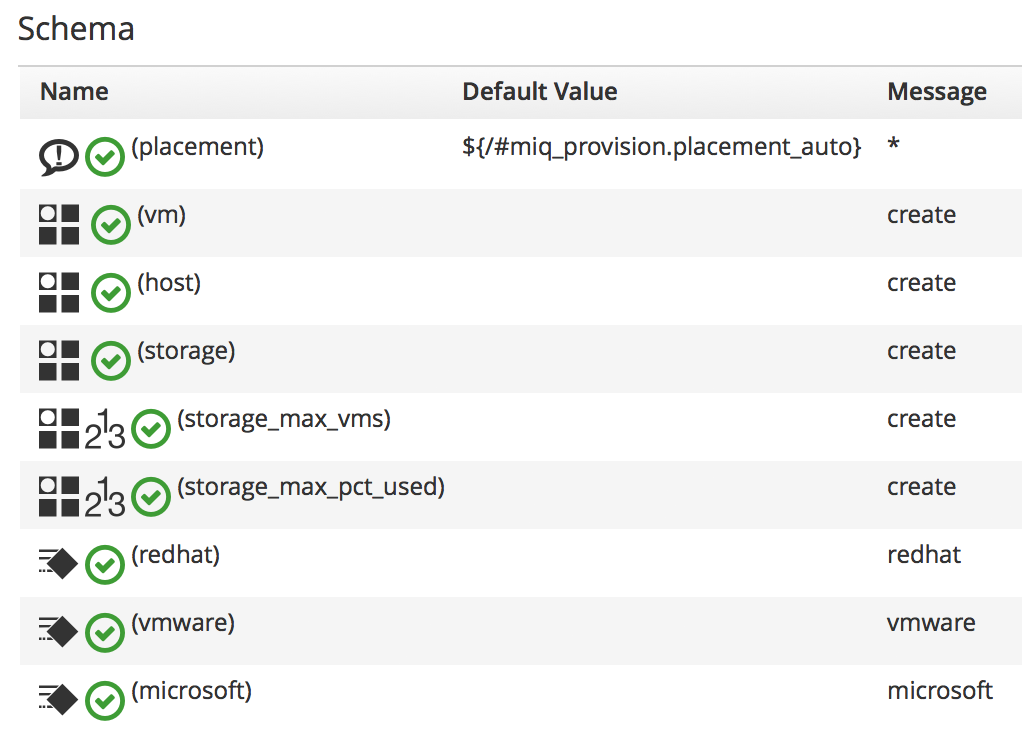
Figure 2. Schema for the /Infrastructure/VM/Provisioning/Placement class
We can therefore call any instance of the class as part of the VM provisioning state machine, by appending a message created from a variable substitution corresponding to the provisioning source vendor (i.e. redhat, vmware or microsoft):
/Infrastructure/VM/Provisioning/Placement/default#${/#miq_provision.source.vendor}
In this way we are able to create a generic class and instance definition that contains several methods, and we can choose which method to run dynamically at run-time by using a message.
Assertions
One of the schema field types that we can use is an assertion. This is a boolean check that we can put anywhere in our class schema (assertions are always processed first in an instance). If the assertion evaluates to true the remaining instance schema fields are processed. If the assertion evaluates to false the remainder of the instance fields are not processed.
We can see an example of an assertion (called placement) at the start of the schema for the Placement class (see Schema for the /Infrastructure/VM/Provisioning/Placement class). Placement methods are relevant only if the Automatic check box has been selected at provisioning time, and this check box sets a boolean value miq_provision.placement_auto. The placement assertion checks that this value is true, and prevents the remainder of the instance from running if automatic placement has not been selected.
Another use for assertions is to put a "guard" field in an instance whose methods are applicable only to a single provider. For example we might have an instance that configures VMware NSX software defined networking during the provisioning of a virtual machine. The methods would fail if called during an OpenStack provisioning operation, but we can add an assertion field to the instance, as follows:
'${/#miq_provision.source.vendor}' == 'VMware'
This will return true if the provisioning operation is to a VMware provider, but false otherwise, so preventing the methods from running in a non-VMware context.
Collections
As we have seen, there is a parent-child relationship between the $evm.root object (the one whose instantiation took us into the Automation Engine), and subsequent objects created as a result of following schema relationships or by calling $evm.instantiate.
If a child object has schema attribute values, it can read or write to them by using its own $evm.object hash (e.g. we saw the use of $evm.object['username'] in Using Schema Variables). Sometimes we need to propagate these values back up a parent or $evm.root object, and we do this using collections.
We define a value to collect from our instance in the Collect schema column, using this syntax:
propagated_variable_name = schema_variable_name
If the first variable specified has a leading '/', the value will be propagated up to $evm.root, i.e.
/variable_name = schema_variable_name
This will then be available to other methods in the workspace as $evm.root['variable_name']. If the first variable does not have a leading '/', i.e.
variable_name = schema_variable_name
This will then be available to a parent instance that called us as $evm.object['variable_name']. This second form is most typically used after a method has called another using $evm.instantiate. Any variables set by the instantiated instance will be available to the calling method in $evm.object.
We can also specify more than one value to collect, by separating values as a semi-colon delimited list, i.e.
var1 = schema_var1; var2 = schema_var2
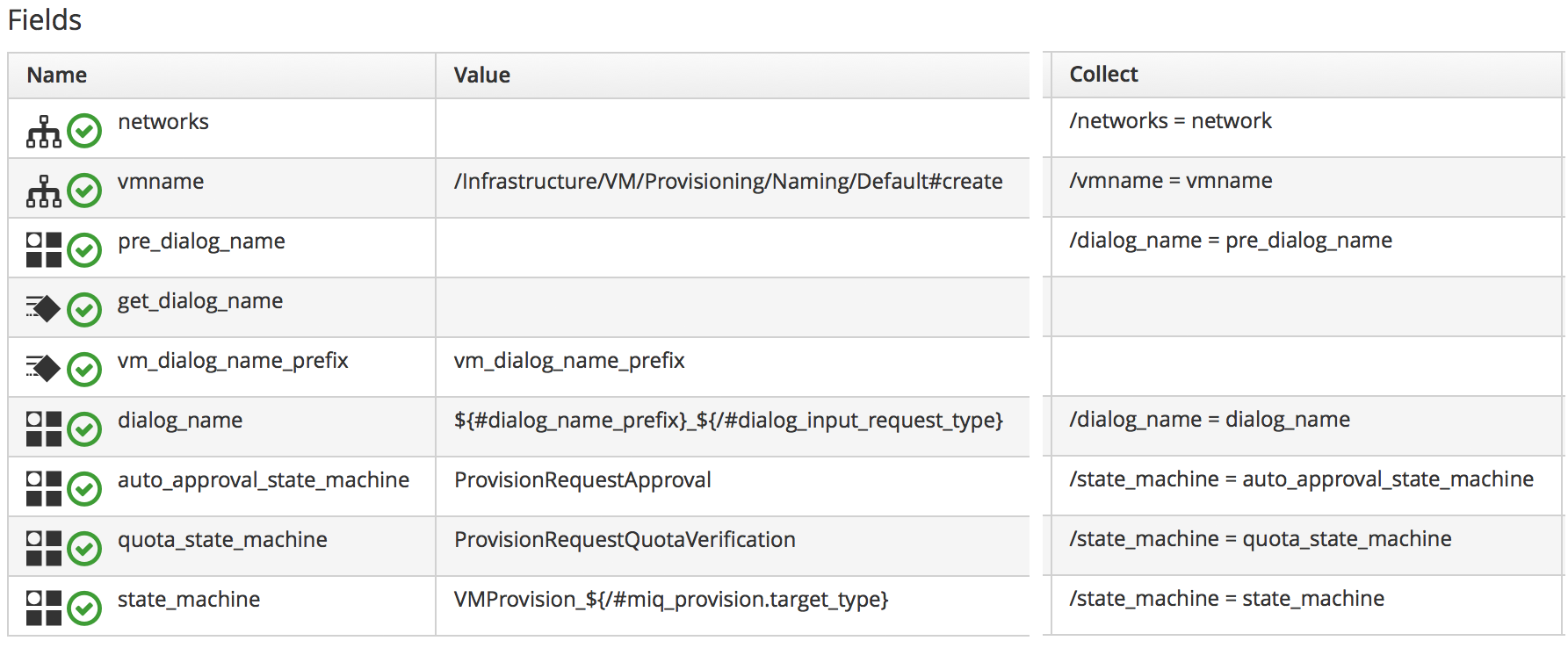
Figure 3. Collections defined in the schema of a provisioning profile
This Provisioning Profile has several schema attributes defined, such as dialog_name and auto_approval_state_machine. The Collect value makes these attribute values available to any other method in the workspace as $evm.root['dialog_name'] and $evm.root['state_machine'].
Calling a Non-Existent Instance
We can optionally add a .missing instance to a class which will be executed if the actual instance name referenced in a calling URI doesn’t exist. This is used in several places in the Automate Datastore, and an example can be seen in the provisioning profile class (see A .missing instance defining a catch-all provisioning profile). Group name-specific profiles can be created to handle VM provisioning options on a per-group basis, and a profile for the EvmGroup-super_administrator group is provided out-of-the-box (see The Provisioning Profile for more details). The .missing instance in this class acts as a catch-all profile for those user groups that don’t have specifically-defined profiles.

Figure 4. A .missing instance defining a catch-all provisioning profile
To support the requirements of the new Ansible Tower provider, CloudForms 4.1/ManageIQ Darga extended the .missing functionality to allow the missing instance name to be caught in a variable called _missing_instance. This allows us to use the variable in a substitution string as the value of a schema attribute (see Catching the missing instance name in the _missing_instance variable).
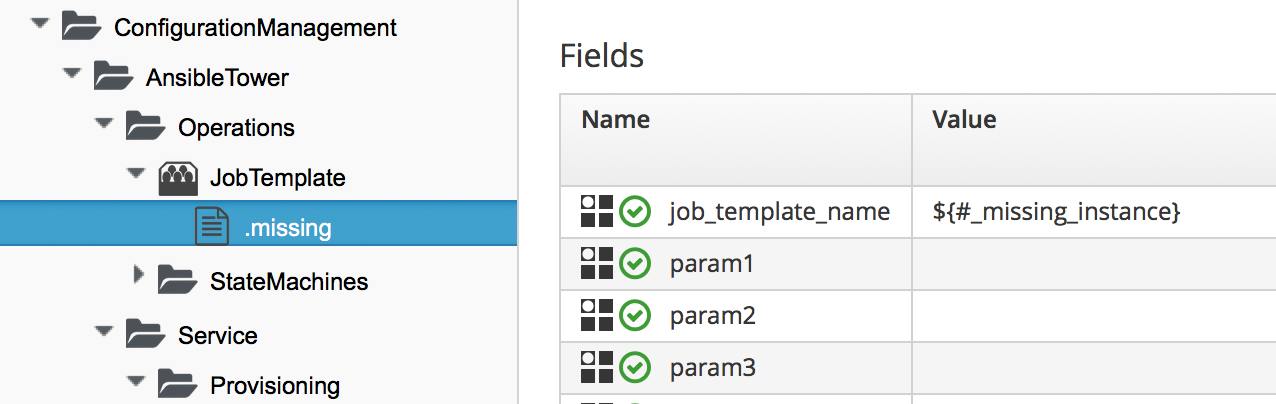
Figure 5. Catching the missing instance name in the _missing_instance variable
For example if we were to call the non-existant URI /ConfigurationManagement/AnsibleTower/Operations/JobTemplate/configure_database_server, the .missing instance would be run with the job_template_name attribute given the run-time value of configure_database_server.
Summary
This chapter completes our coverage of the objects and techniques that we work with in the Automate Datastore. The schema and instance features that we’ve learnt about here are used less frequently, but are still very useful tools to have in our scripting toolbag.